Bias and Variance
Formal Definitions of ML
$S=\left\{\left(x_i, y_i\right)\right\}_{i=1}^N, \quad x \in \mathbb{R}^D, y \in\{-1,+1\}$
$h(\boldsymbol{x} \mid \boldsymbol{w}, \boldsymbol{b})=\boldsymbol{w}^T \boldsymbol{x}+\boldsymbol{b}$ (Linear model)
N: 데이터 수, x: input, y: output이며 -1과 +1 값을 가짐
목표: S를 잘 예측하는 w, b 값을 찾기
Loss function
The squared loss for regression: $L(a,b)=(a-b)^2$
0/1 loss for classification: $L(a,b)=1_{[a≠b]}$ or $1_{[sign(a) ≠ sign(b)]}$
Learning objective (optimization)
$\operatorname{argmin}_{w, b} \sum_{i=1}^N L\left(y_i, h\left(\boldsymbol{x}_i \mid \boldsymbol{w}, \boldsymbol{b}\right)\right)$
Generalization in ML
- 머신러닝에서 일반화는 모델이 학습한 데이터뿐만 아니라 새로운 보이지 않는 데이터에서도 잘 수행할 수 있는 능력
- 학습 알고리즘은 훈련 예제의 정확도를 최대화해야 하지만 overfitting은 막아야 한다.
- Overfitting = poor generalization

Generalization Error
학습의 목표는 학습 데이터 자체의 정확한 표현을 학습하는 것이 아니라, 데이터를 생성하는 통계적 모델을 구축하는 것
True distribution: 𝑃 (𝒙, 𝒚)
- 우리에게 알려지지 않은 모든 가능한 경우
- 훈련 및 테스트 데이터는 P(x, y)에서 생성됨
- Assumption: iid (independent and identically distributed) 독립적이고 동일하게 분포
Train(훈련): 가설 h(x)을 fit
- P(x, y)에서 생성된 training data $S=\left\{\left(x_i, y_i\right)\right\}_{i=1}^N$ 사용
Generalization Error: $L_p(h)=E_{P(\boldsymbol{x}, \boldsymbol{y})}[L(\boldsymbol{y}, h(\boldsymbol{x}))]$
- 모든 가능한 경우에 대한 예측 손실
- 일반화: 이전에 보지 못한 입력에 대해 잘 수행할 수 있는 능력
Underfitting(과소적합): 일반화 오차 < 훈련 오차
훈련 오차가 충분히 낮지 않음
Overfitting(과적합): 일반화 오차 > 훈련 오차
훈련 오차와 테스트 오차의 차이가 너무 큼
머신러닝 알고리즘을 잘 학습하는 방법
- 훈련 오차를 작게 만듭니다.(Overfitting을 만든다)
- 훈련 오차와 테스트 오차의 차이를 작게 만듭니다.
일반적으로 Overfitting이 발생하는 이유는 데이터가 적거나 없는 분포가 있기에 발생한다. 훈련 오차를 줄이기 위하여 Model의 Capacity를 증가하는데 그 분포 때문에 복잡하게 된다.
Occam’s Razor (A Principle of Parsimony)
필요하지 않은 가정을 하지 말라
불필요한 가정을 최소화하고 간단한 설명을 선호하는 머신러닝 원리로, 주어진 증거에 가장 일치하는 간단하면서도 효과적인 설명을 선호한다. 이는 모델의 복잡성을 최소화하고 과적합을 방지하여 더 간결하고 효과적인 예측을 가능케 한다. 다양한 분야에서 적용되며 항상 적용되는 절대 규칙은 아니지만, 머신러닝에서는 효율적인 모델 구축을 위한 중요한 원칙 중 하나이다.
Regularization
머신러닝 알고리즘에서는 종종 가설 공간 내에서 한 해결책에 대한 선호를 다른 것보다 나타내야 할 필요가 있습니다. 선형 회귀에서의 가중치 감쇠(weight decay)와 같이 이를 나타내는 일반적인 기법은 다음과 같습니다
$J(w)=(\text { error })+\lambda w^T w$
- 𝜆 controls the strength of a preference for smaller weight
- 𝜆 = 0: no preference, a large 𝜆: a smaller weight
- The penalty term is called as a regularizer
정규화의 주요 목표는 훈련 오차를 최소화하는 것이 아니라 일반화 오차를 감소시키는 데 있습니다. 과도하게 복잡한 모델을 피하고, 보다 일반적으로 새로운 데이터에 적용 가능한 모델을 만들기 위해 정규화는 필요한 훈련과 일반화의 균형을 유지하는 데 중요한 역할을 합니다.
Bias/Variance Decomposition
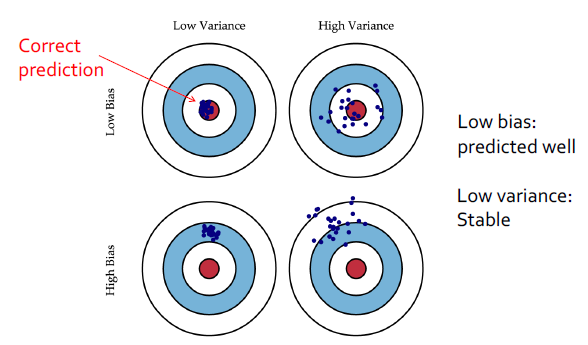
머신러닝에서의 추정기(estimator)의 편향과 분산 사이에는 트레이드오프가 존재합니다. 이는 선형 회귀에서의 가중치 감쇠(weight decay)와 같은 기법에서 나타나는데요.
편향(bias)과 분산(variance)은 추정기의 두 가지 에러 소스로, 다음과 같이 정의됩니다:
편향(Bias): 함수의 실제 값과의 기대치로부터의 예상 편차
분산(Variance): 데이터를 다르게 샘플링했을 때 얻는 예상 추정기 값으로부터의 편차
예측 모델의 복잡도를 증가시키면 분산은 증가하고 편향은 감소하는 경향이 있습니다. 이러한 트레이드오프를 이해하고 적절한 모델 복잡도를 선택하는 것은 모델의 성능을 향상시키는 핵심입니다.
결론
과적합(Overfitting):
- 높은 분산은 과적합을 의미합니다.
- 모델 클래스가 불안정합니다.
- 모델 복잡성이 증가함에 따라 분산이 증가합니다.
- 더 많은 훈련 데이터로 분산을 감소시킬 수 있습니다.
과소적합(Underfitting):
- 높은 편향은 과소적합을 나타냅니다.
- 분산이 없어도 모델 클래스의 오차가 높습니다.
- 편향은 모델 복잡성 감소에 따라 감소합니다.
- 훈련 데이터 크기와는 관련이 없습니다.
※ LG AImers 4차 교육을 수강하고 작성한 글입니다.
느낀점
Occam’s Razor은 머신러닝에서도 중요하지만 인생에서도 좋은 이론 같다.
불필요하게 어렵게 생각하지 말자!
'DevLog > Education' 카테고리의 다른 글
| ML개론 Part 1 (0) | 2024.01.16 |
|---|---|
| AI 윤리 Part 1 (0) | 2024.01.05 |

